July 10, 2020
Category: The package java.util.concurrent.atomic
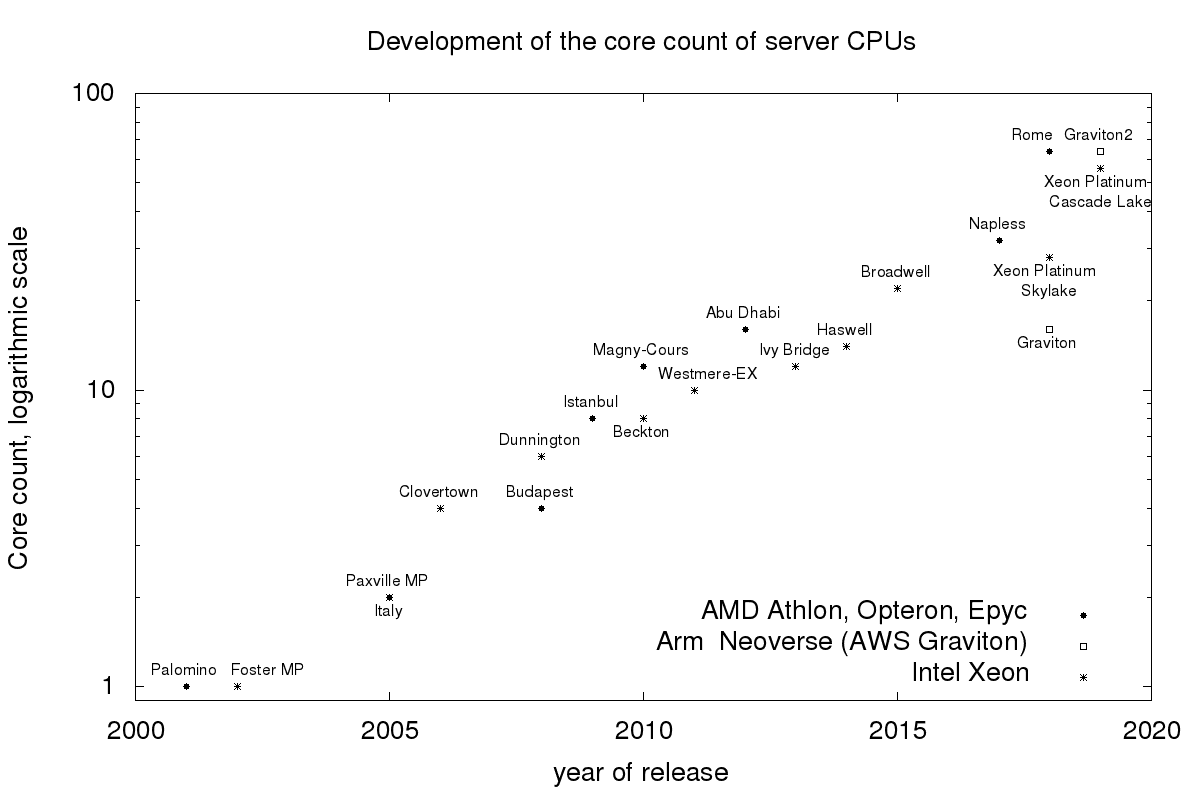
The number of current CPUs cores is growing exponentially, see the following figure for the development of current server CPUs. Therefore I am looking at the scalability of different data structures. The last time we looked at concurrent queues this time we look at concurrent hash maps.
We look at three different hash maps, two from the JDK and one from the open-source library JCTools.
SynchronizedMap A thread-safe hash map from the JDK. It can be created by calling Collections. on java.. It is simply the not thread-safe HashMap surrounded by a single lock.
java. is a dedicated implementation of a thread-safe hash map from the JDK. It uses one lock per array element when updating the map. For read-only operations, this map does not need any locks but only volatile reads.
org. from the open-source library JCTools does not use any locks. For updates, it instead uses the atomic compare and set operation. And for read-only operations, it uses similar to ConcurrentHashMap only volatile reads. This map only supports the java. API till JDK 1.6.
The hash maps have to basic operations, one to put a key-value pair into the map and one to get a value for a key back. Therefore I use two benchmarks. Read-only using get and write only, using put. Let us first look at the benchmark for get. This benchmark uses a prefilled map and always gets the same element out of the map. I use the OpenJDK JMH project to implement the benchmark:
@State(Scope.Benchmark)
public abstract class AbstractBenchmark {
private final Map forGet;
Integer element = 1;
public AbstractBenchmark() {
forGet = create();
Random random = new Random();
final int maxKey = 10000;
for (int i = 0; i < 1000; i++) {
forGet.put(random.nextInt(maxKey), element);
}
forGet.put(100, element);
}
@Benchmark
public Object get() {
return forGet.get(100);
}
}
Here are the results for an Intel Xeon Platinum 8124M CPU @ 3.00GHz with two sockets with eighteen cores per socket and two hardware threads per core. I used Amazon Corretto 11 as JVM.
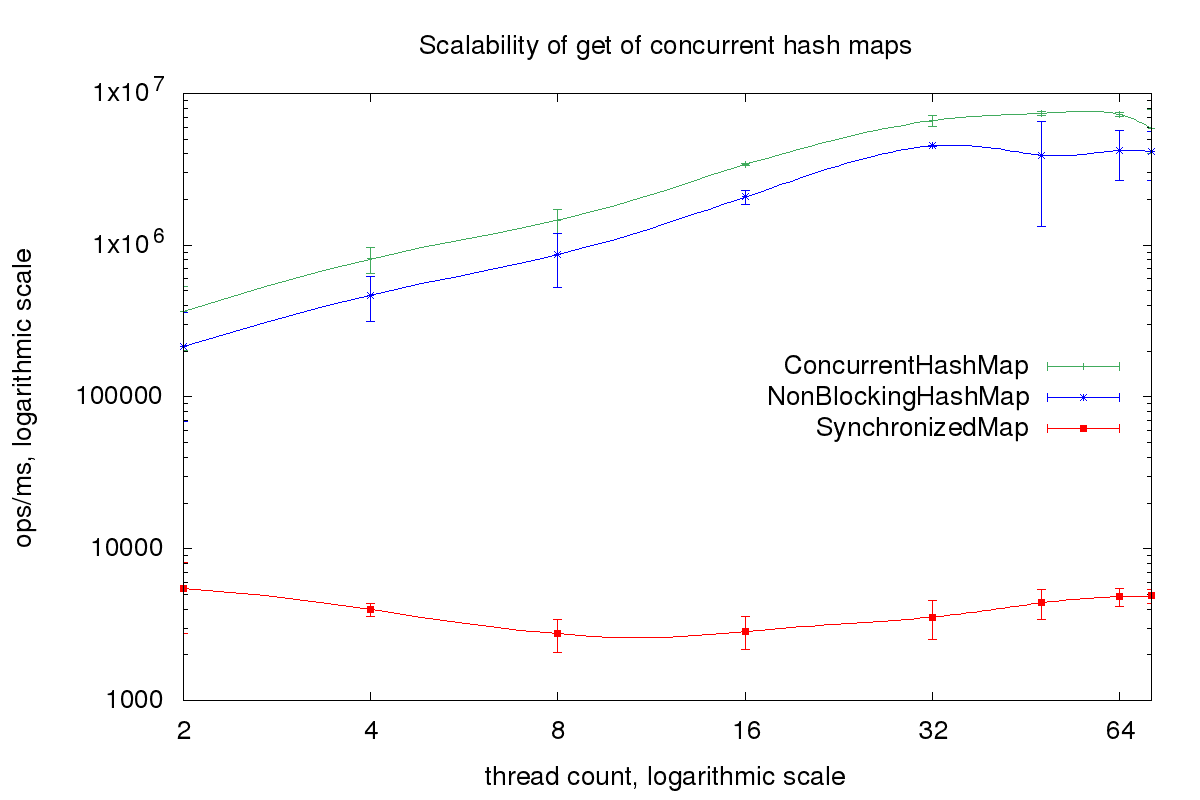
The read performance from ConcurrentHashMap and NonBlockingHashMap is impressive. To see how good the performance really is we compare it with a baseline benchmark, e.g. a benchmark which only returns a constant:
@State(Scope.Benchmark)
public class BaselineBenchmark {
int x = 923;
@Benchmark
public int get() {
return x;
}
}
If we run it one the same Intel Xeon machine again, we see that the read performance is almost as fast as the baseline:
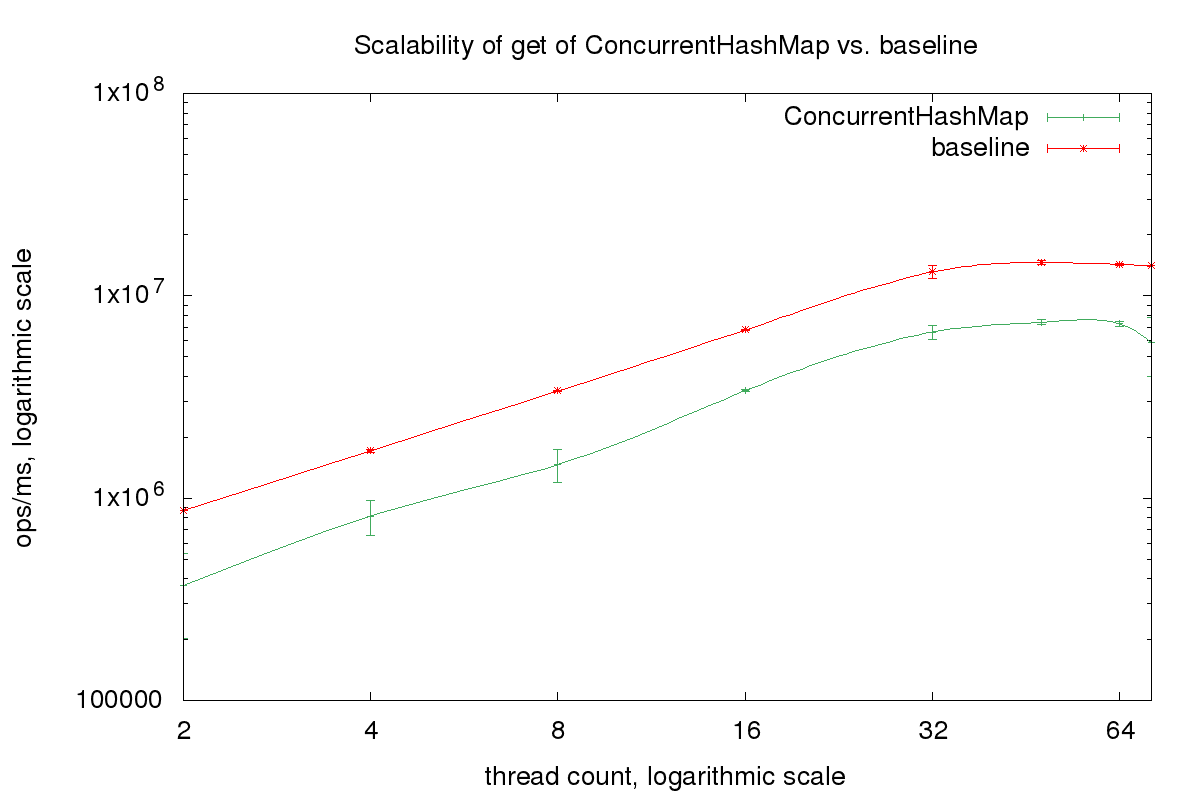
Now let us look at the write-only benchmark. This time we put random keys with a constant value into the map:
@State(Scope.Benchmark)
public abstract class AbstractBenchmark {
private Map forPut;
public static final int MAX_KEY = 10000000;
Integer element = 1;
protected abstract Map create();
@Setup(Level.Iteration)
public void setup() {
forPut = create();
}
@Benchmark
public Object put() {
int key =
ThreadLocalRandom.current().
nextInt(MAX_KEY);
return forPut.put(key, element);
}
}
If we run this benchmark on the Intel Xeon we see the advantage of lock free algorithms. While ConcurrentHashMap only scales up to 16 threads NonBlockingHashMap scales till the maximum thread count of 72 threads.
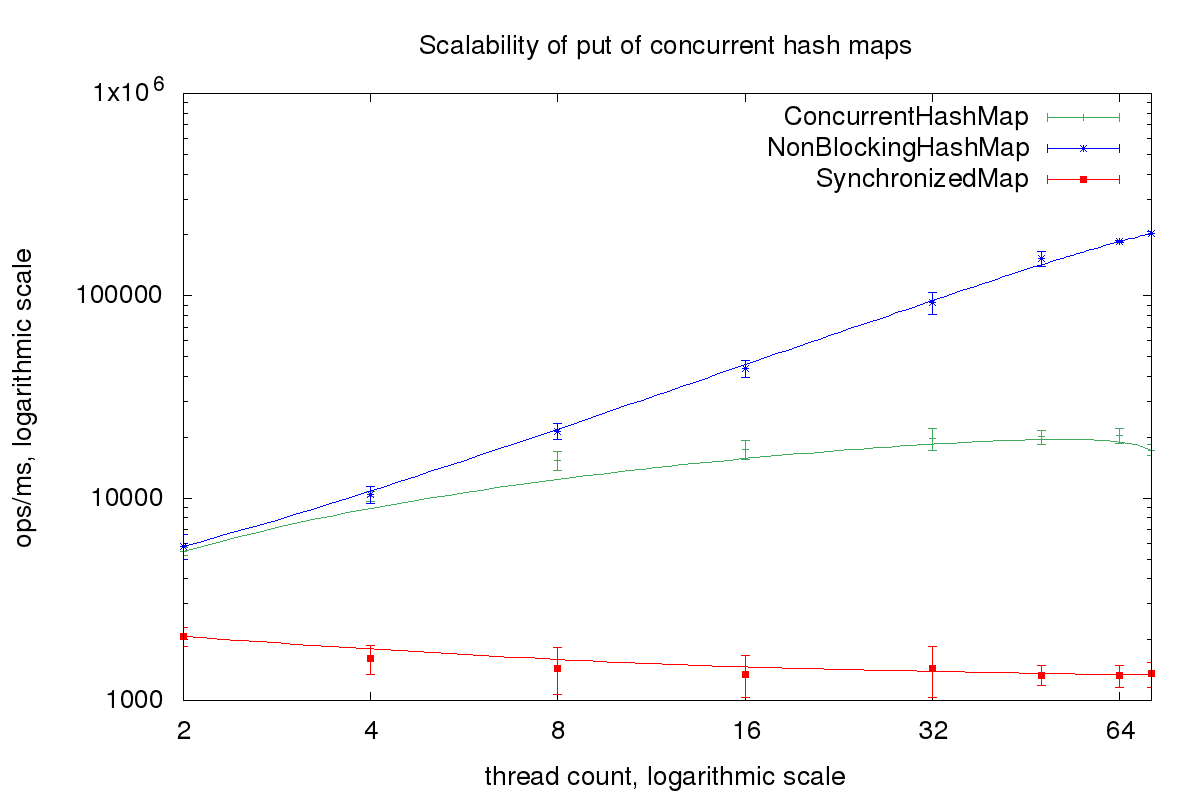
You can download the source code for all the benchmarks from GitHub here.
Disqus and Reddit commentators suggested testing with a higher concurrencyLevel. So here is the same benchmark with a concurrencyLevel of 72 compared to the default concurrencyLevel of 12:
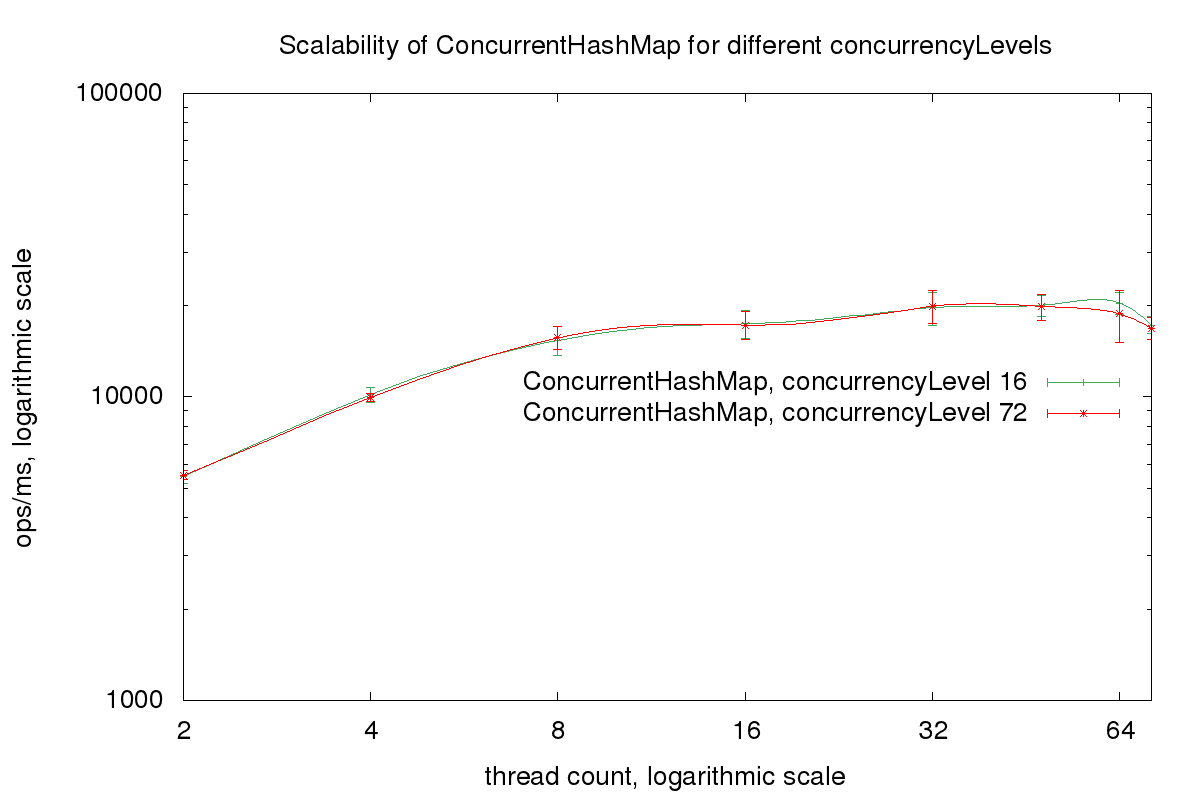
The concurrencyLevel does not affect the scalability of the ConcurrentHashMap. Why?
The meaning of the concurrencyLevel changed between JDK 7 and JDK 8. In JDK 7 the hash map consisted of an array of segments. Each segment consisted of an array of lists of key-value pairs and extended the class java.. The size of this array of segments was fixed and was specified by the concurrencyLevel. The idea was that if many threads are accessing the hash map it is better to use multiple locks and smaller segments. And if only a small number of threads are accessing the hash map a lower number of locks fits better.
But with JDK 8 the ConcurrentHashMap uses only one array of lists of key-value pairs. And each array element is used as a lock. The concurrencyLevel is now just another way to specify the capacity of the map, as we can see in the constructor of ConcurrentHashMap:
public ConcurrentHashMap(int initialCapacity,
float loadFactor, int concurrencyLevel) {
if (!(loadFactor > 0.0f) || initialCapacity < 0
|| concurrencyLevel <= 0)
throw new IllegalArgumentException();
if (initialCapacity <
concurrencyLevel) // Use at least as many bins
initialCapacity =
concurrencyLevel; // as estimated threads
long size = (long)(1.0 +
(long)initialCapacity / loadFactor);
int cap = (size >= (long)MAXIMUM_CAPACITY) ?
MAXIMUM_CAPACITY : tableSizeFor((int)size);
this.sizeCtl = cap;
}
The benchmark for the concurrent hash map shows what is possible in Java. Read-only performs is almost as good as the baseline since it consists only of volatile reads. And by using a non-blocking algorithm using the atomic compare and set operation it is possible to implement write operations which scale.
© 2020 vmlens Legal Notice Privacy Policy