July 03, 2020
Category: The package java.util.concurrent.atomic
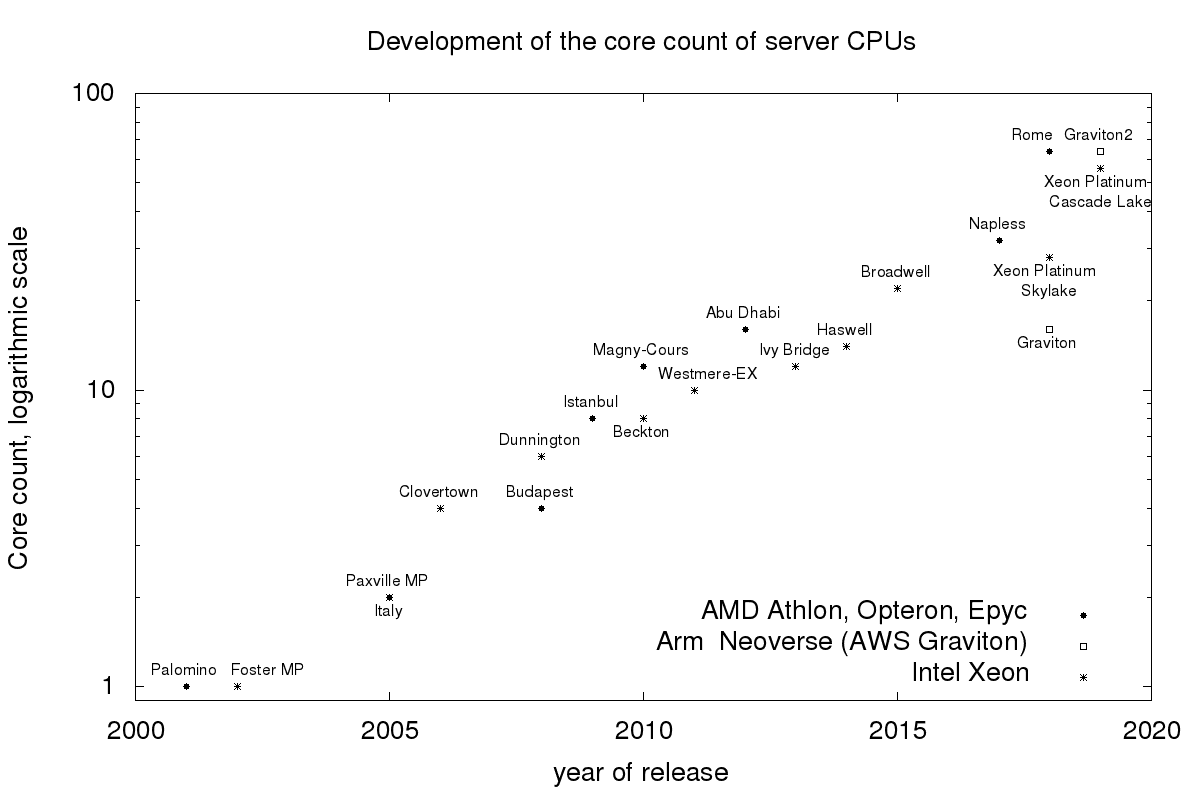
The core count of current CPUs is growing exponentially. See the following figure for the development of the core count of current server CPUs. So the scalability of concurrent data structures becomes more and more important. Today we look at the scalability of one such data structure: Concurrent Queues.
Every time two threads communicate asynchronously, chances are high that a queue is involved. Web servers like tomcat use queues to dispatch incoming requests to worker threads. Frameworks like Akka use queues for the communication of their actor classes.
We will look at the scalability of the following four queues, three bounded queues, and one unbounded queue:
java.util.concurrent.ArrayBlockingQueue : A bounded queue from the JDK. The queue uses an array to store its elements and a single lock for both reading and writing.org.jctools.queues.MpmcArrayQueue : A bounded queue from the open-source library JCTools. It also uses an array to store its elements. But instead of a lock, it uses the atomic compare and swap operation for the concurrent update of the array.java.util.concurrent.LinkedBlockingQueue : A bounded queue from the JDK. The queue uses a linked list to store its elements and two locks. One lock for reading and one lock for writingjava.util.concurrent.ConcurrentLinkedQueue : An unbounded queue from the JDK. It also uses a linked list to store its elements. But instead of a lock, it uses the atomic compare and swap operation for the concurrent update of the list.org.jctools.queues.MpmcUnboundedXaddArrayQueue : An unbounded queue from the open-source library JCTools. The queue uses multiple arrays or chunks to store its elements. It uses atomic operations to calculate the index in those chunks for reading and writing.When testing we need to decide in which state we want to test the queues. I opted for a test in a steady state. And to test the queues when they are only slightly filled. This avoids that the garbage collection falsifies the measured times. I use the following JMH benchmark:
@State(Scope.Benchmark)
public abstract class AbstractBenchmark {
public static final int QUEUE_SIZE = 1024;
private static long DELAY_PRODUCER = 1024;
public AbstractBenchmark(Queue queue) {
this.queue = queue;
}
private final Queue queue;
Integer element = 1;
@Setup(Level.Iteration)
public void setup() {
synchronized (queue) {
queue.clear();
}
}
@Benchmark
@Group("g")
@GroupThreads(1)
public void put(Blackhole bh, Control control) {
bh.consumeCPU(DELAY_PRODUCER);
while (!queue.offer(element) &&
!control.stopMeasurement) {
}
}
@Benchmark
@Group("g")
@GroupThreads(1)
public Object take(Blackhole bh, Control control) {
Object result = queue.poll();
while (result == null &&
!control.stopMeasurement) {
result = queue.poll();
}
return result;
}
}
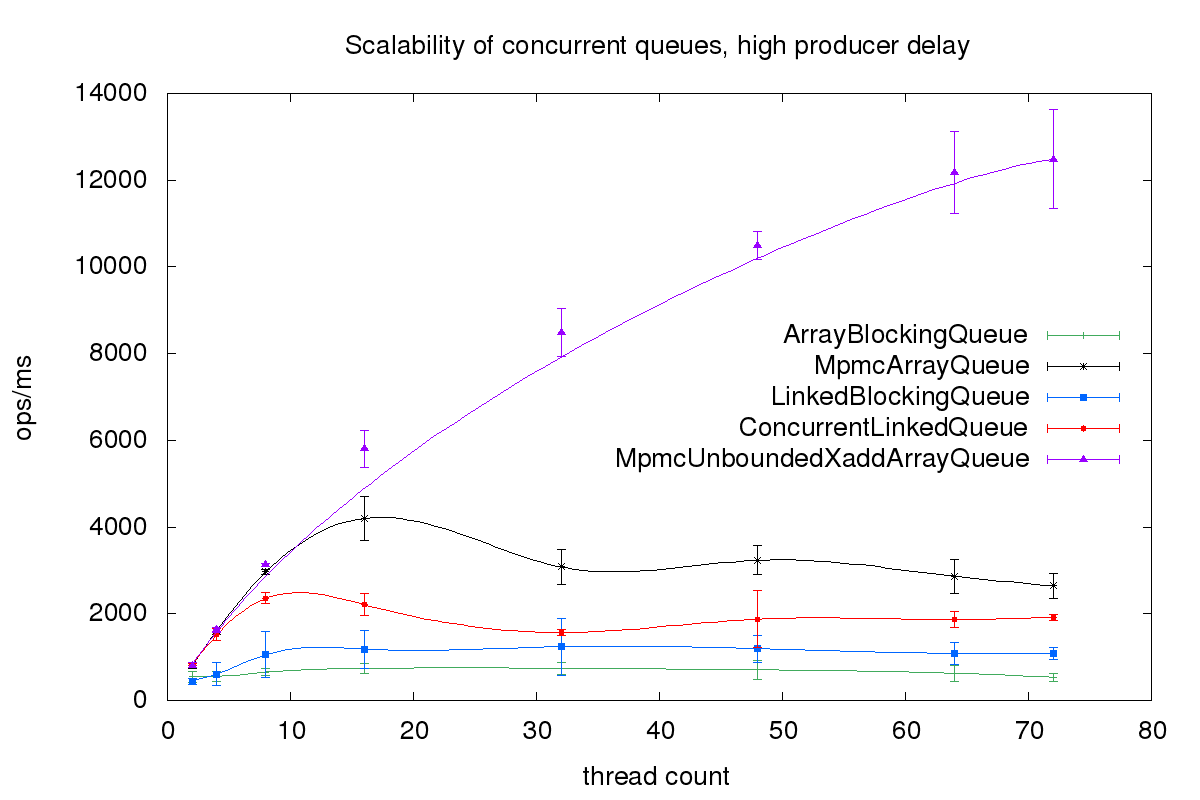
Here are the results for Intel Xeon Platinum 8124M CPU @ 3.00GHz with two sockets with eighteen cores per socket and two hardware threads per core. I used Amazon Corretto 11 as JVM. I use a high delay for the consumer threads, 1024.
Now we use a much slower delay, 32, and repeat the benchmark.
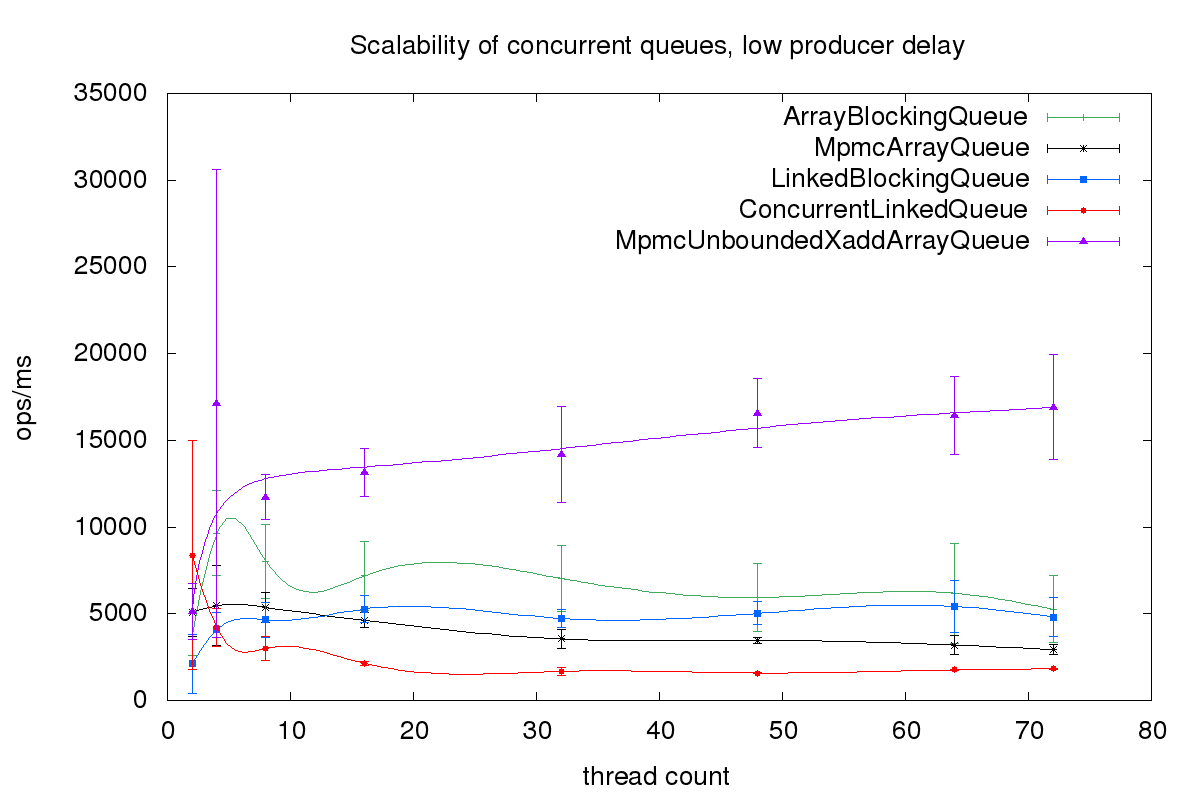
The first benchmark is more realistic. The producer threads normally do not only publish to the queue but also do some other work. In this benchmark, the lock-free queues outperform the lock-based queues.
You can download the source code from GitHub here and test the scalability in your production environment.
To scale queues is hard. Since they are first in first out all writing threads compete for the next position to write to. And all reading threads compete for the next element to read. But as long as the queue is not overloaded the lock-free queues using compare and swap outperform the lock-based queues. And the unbounded queue org. outperforms all other queues, independent of the workload.
© 2020 vmlens Legal Notice Privacy Policy