August 05, 2020
Category: The package java.util.concurrent.atomic
ARM CPUs are coming to Java. Amazon offers cloud instances based on ARM-compatible processors. And there is now a new JEP to create an OpenJDK port for Windows on ARM. And Apple plans to use ARM Processors for its Macs and Macbooks.
What is the difference between ARM and x86 when we program in Java? As long as you follow the rules: None. So let us break the rules
The following test leads to different results on the two processor types. We use a dedicated tool for those types of tests, the OpenJDK tool jcstress. The test consists of two methods which are annotated with the annotation @Actor. The annotated methods get called from different threads:
public class TestReorderWriteWrite {
SingeltonWithDataRace singelton = new SingeltonWithDataRace();
@Actor
public void actor1(II_Result r) {
if (singelton.instance().initialized) {
r.r1 = 1;
} else {
r.r1 = 0;
}
}
@Actor
public void actor2(II_Result r) {
if (singelton.instance().initialized) {
r.r2 = 1;
} else {
r.r2 = 0;
}
}
}
The class Singelton checks if the variable instance is null and if yes, creates a new SingeltonValue:
public class SingeltonWithDataRace {
SingeltonValue instance;
public SingeltonValue instance() {
if (instance == null) {
instance = new SingeltonValue();
}
return instance;
}
}
SingeltonValue sets the variable initialized to true in the constructor:
public class SingeltonValue {
boolean initialized;
public SingeltonValue() {
initialized = true;
}
}
Since we always first write to the variable initialized and then to instance, the variable initialized should always be true. If I run this test on my development machine, an Intel i5 4 core CPU, I see the following results.
Observed state Occurrences Expectation
1, 1 52368551 ACCEPTABLE
So as expected the variable initialized is always true. Running the same test on an ARM AWS Graviton Processor with 2 vpus gives the following results:
Observed state Occurrences Expectation
0, 0 0 FORBIDDEN
0, 1 7 ACCEPTABLE_INTERESTING
1, 0 14 ACCEPTABLE_INTERESTING
1, 1 57,117,820 ACCEPTABLE
On ARM the variable initialized is sometimes false, the state 0 1 and 1 0. So on ARM the write to instance and to initialized can be reordered, when we read the variables from a different thread. Why?
CPU Cores cache the values from the main memory in caches. This bridges the gap between the fast core and the slower memory system. A read from the level 1 cache is about 200 times faster than a read from the main memory.
L1 cache reference 0.5 ns Branch mispredict 5 ns L2 cache reference 7 ns 14x L1 cache Main memory reference 100 ns 20x L2 cache, 200x L1 cache
From jboner/latency.txt
The result of the test is the effect of this cache system. The behavior of the cache system is specified in a memory model. A memory model answers the question: What happens when multiple threads access the same memory location?
The two processor types have different memory models. The ARM memory model allows the reordering of two writes to different memory locations. And the x86 memory model forbids this. This is the reason why the test leads to different results on the different processor architectures.
Other reorderings like read and write to different memory locations are allowed by both memory models.
The following test shows this. Again we use two methods annotated with @Actor. The two methods run in different threads during the test. The first method writes to the field first and reads from the field second. The second method writes to the field second and reads from the field first:
public class TestReorderReadWrite {
private int first;
private int second;
@Actor
public void actor1(II_Result r) {
first = 1;
r.r1 = second;
}
@Actor
public void actor2(II_Result r) {
second = 1;
r.r2 = first;
}
}
And here are the results from a test run on my development machine, an Intel i5 4 core CPU:
Observed state Occurrences Expectation
0, 0 5,688,756 ACCEPTABLE_INTERESTING
0, 1 46,185,263 ACCEPTABLE
1, 0 26,244,626 ACCEPTABLE
1, 1 86 ACCEPTABLE
Here is the result from the ARM AWS Graviton Processor with 2 vpus:
Observed state Occurrences Expectation
0, 0 5,361,697 ACCEPTABLE_INTERESTING
0, 1 55,586,568 ACCEPTABLE
1, 0 25,740,292 ACCEPTABLE
1, 1 4 ACCEPTABLE
Sometimes both method reads the default value zero. This means that the read and the write to the variables were reordered.
If we want to write meaningful multi-threaded programs we need a way to tell the processor that he should stop reordering. At least at specific points. The processor provides memory barriers for that. If we annotate the field with a volatile variable the JVM generates memory barriers. Here is the assembler code from my development machine, an Intel i5 4 core CPU:
movl $0x1,0xc(%r10) ;*putfield first lock addl $0x0,(%rsp) : Memory Barrier mov 0x10(%r10),%edx ;*getfield second
The JVM inserts the statement lock addl. This makes sure that read and writes do not get reordered.
When we write Java we do not write for a specific processor architecture. So Java also needs a memory model. A memory model which answers the question, what happens when multiple threads access the same memory location, for Java.
The answer is the following:
Sequential consistency means that reads and writes are not reordered. A run of a multi-threaded program is simply one specific interleaving of the source code statements of the different threads.
A Java program is only sequential consistent when it does not contains data races. A data race is a read and a write or two writes to the same memory location which is not ordered by synchronization actions. Synchronization actions like the read and write from a volatile field create an order between multiple threads, the happens-before order. For example the write to a volatile variable happens-before all subsequent volatile reads from this variable. And if all memory accesses can be ordered through this happens-before relation our program is data race free.
The processor core is not the only system that reorders statements. The compiler also reorders statements to improve the performance. Therefore we need a memory model at the language level. Only we, the programmers, can tell how our program needs to be ordered.
But we do not control at which hardware or JVM our program runs on, so we need a way to specify this order in the program code. We do this by the synchronization actions of the Java Memory Model.
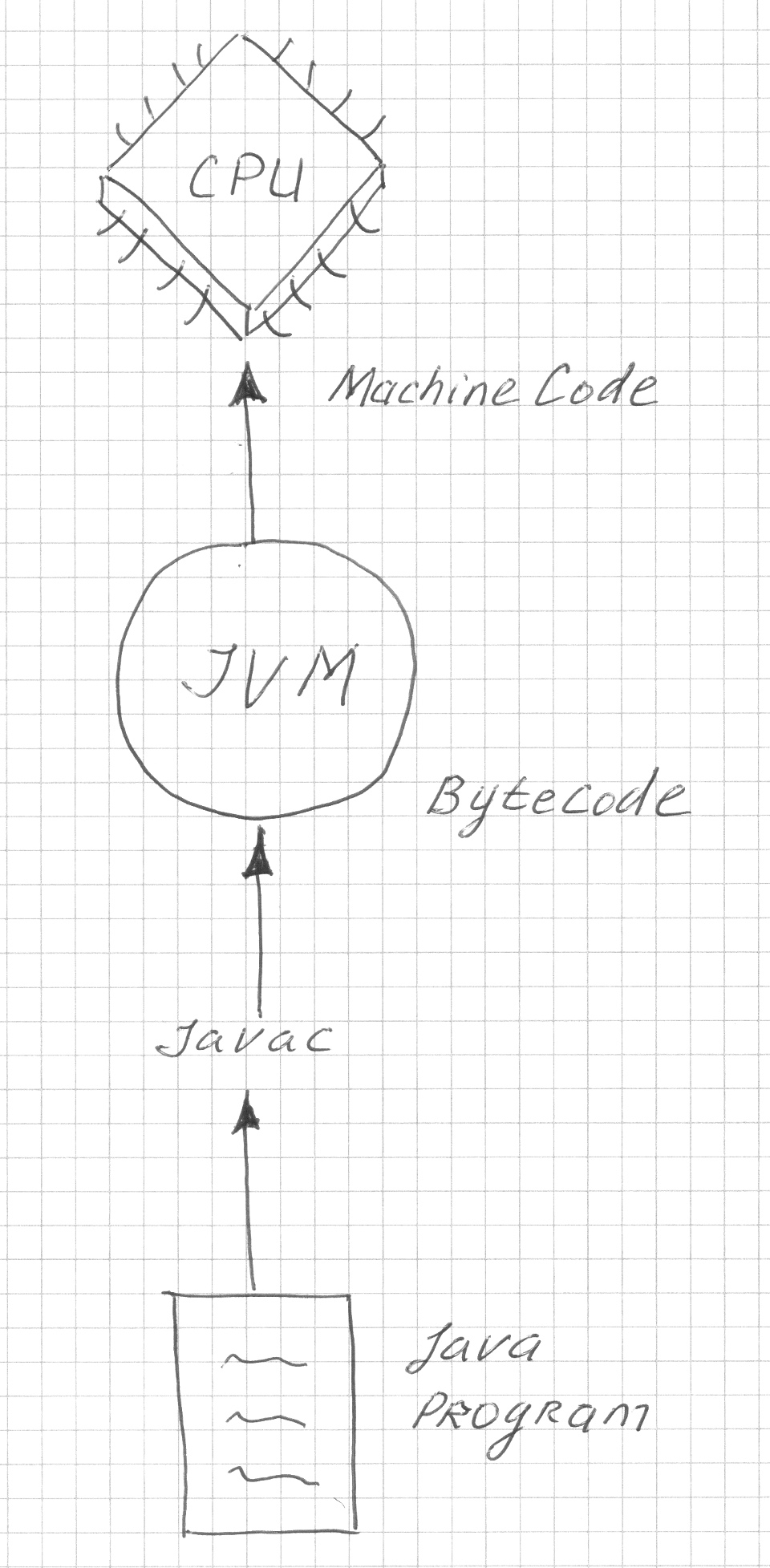
Typical suspects for reordering our program are the processor and the JVM compiler, which compiles the bytecode to machine code.
Sarita V. Adve and Hans-J. Boehm give a nice overview of the reasoning which led to the Java Memory Model in the paper, Memory Models: A Case For Rethinking Parallel Languages and Hardware. And Aleksey Shipilёv, the developer of the tool JCstress, has written a comprehensive blog post over the Java Memory Model. And Paul E. Mckenney gives a detailed view of the cache system in the paper, Memory Barriers: a Hardware View for Software Hackers
As we have two writes to different variables can only be reordered on ARM CPUs, while it is forbidden on x86 CPUs. The reordering of reading and writing from different variables can be reordered on both CPU types.
When I first read about the Java Memory Model in the book Java Concurrency in Practice, from Brian Goetz et al. I did not understand it. It took long for me to accept that we need to tell the JVM how memory reads and writes should be ordered. So I am happy that we have now another system, ARM, which reorders read and writes. And that we can write small Java programs that demonstrate that we need the Java Memory Model.
© 2020 vmlens Legal Notice Privacy Policy