January 17, 2020
Category: The package java.util.concurrent.atomic
When writing thread-safe classes the main issue is to separate the data into multiple independent parts. And to choose the right size for those parts. If the part is too small our class is not thread-safe. If the part is too large the class is not scalable.
Let us look at an example which illustrates that point:
Suppose we want to track how many people live in a city. We want to support two methods, one to get the current count of people living in a city and one to move a person from one city to another. So we have the following interface:
public interface CityToCount {
static final String[] ALL_CITIES =
new String[] { "Springfield" , "South Park" };
static final int POPULATION_COUNT = 1000000;
void move( String from, String to );
int count(String name);
}
You can download the source code of all examples from GitHub here.
Since we want to use this interface from multiple threads in parallel we have to options to implement this interface. Either use the class java.util.concurrent.ConcurrentHashMap or uses the class java.util.HashMap and a single lock. Here is the implementation using the class java.util.concurrent.ConcurrentHashMap:
public class CityToCountUsingConcurrentHashMap
implements CityToCount {
private ConcurrentHashMap<String, Integer> map =
new ConcurrentHashMap<String, Integer>();
public CityToCountUsingConcurrentHashMap() {
for (String city : ALL_CITIES) {
map.put(city, POPULATION_COUNT);
}
}
public void move(String from, String to) {
map.compute(from, (key, value) -> {
if (value == null) {
return POPULATION_COUNT - 1;
}
return value - 1;
});
map.compute(to, (key, value) -> {
if (value == null) {
return POPULATION_COUNT + 1;
}
return value + 1;
});
}
public int count(String name) {
return map.get(name);
}
}
The method move uses the thread-safe method compute to decrement the count in the source city. Than compute is used to increment the count in the target city. The count method uses the thread-safe method get.
And here is the implementation using the class java.util.HashMap:
public class CityToCountUsingSynchronizedHashMap
implements CityToCount {
private HashMap<String, Integer> map =
new HashMap<String, Integer>();
private Object lock = new Object();
public CityToCountUsingSynchronizedHashMap() {
for (String city : ALL_CITIES) {
map.put(city, POPULATION_COUNT);
}
}
public void move(String from, String to) {
synchronized (lock) {
map.compute(from, (key, value) -> {
if (value == null) {
return POPULATION_COUNT - 1;
}
return value - 1;
});
map.compute(to, (key, value) -> {
if (value == null) {
return POPULATION_COUNT + 1;
}
return value + 1;
});
}
}
public int count(String name) {
synchronized (lock) {
return map.get(name);
}
}
}
The method move also uses the method compute to increment and decrement the count in the source and target city. Only this time, since the compute method is not thread-safe, both methods are surrounded by a synchronized block. The count method uses the get method again surrounded by a synchronized block.
Both solutions are thread-safe.
But in the solution using ConcurrentHashMap multiple cities can be updated from different threads in parallel. And in the solution using a HashMap, since the lock is around the complete HashMap, only one thread can update the HashMap at a given time. So the solution using ConcurrentHashMap should be better scalable. Let us see.
To compare the scalability of the two implementations I use the following benchmark:
import org.openjdk.jmh.annotations.Benchmark;
import org.openjdk.jmh.annotations.State;
import org.openjdk.jmh.annotations.Scope;
@State(Scope.Benchmark)
public class CityToCountBenchmark {
public CityToCount cityToCountUsingSynchronizedHashMap
= new CityToCountUsingSynchronizedHashMap();
public CityToCount cityToCountUsingConcurrentHashMap
= new CityToCountUsingConcurrentHashMap();
@Benchmark
public void synchronizedHashMap() {
String name = Thread.currentThread().getName();
cityToCountUsingSynchronizedHashMap.move(name, name + "2");
}
@Benchmark
public void concurrentHashMap() {
String name = Thread.currentThread().getName();
cityToCountUsingConcurrentHashMap.move(name, name + "2");
}
}
The benchmark uses jmh, an OpenJDK framework for micro-benchmarks. In the benchmark, I move people from one city to another. Each worker thread updates different cities. The name of the source city is simply the thread id and the target city the thread id plus two. I ran the benchmark on an Intel i5 4 core CPU with these results:
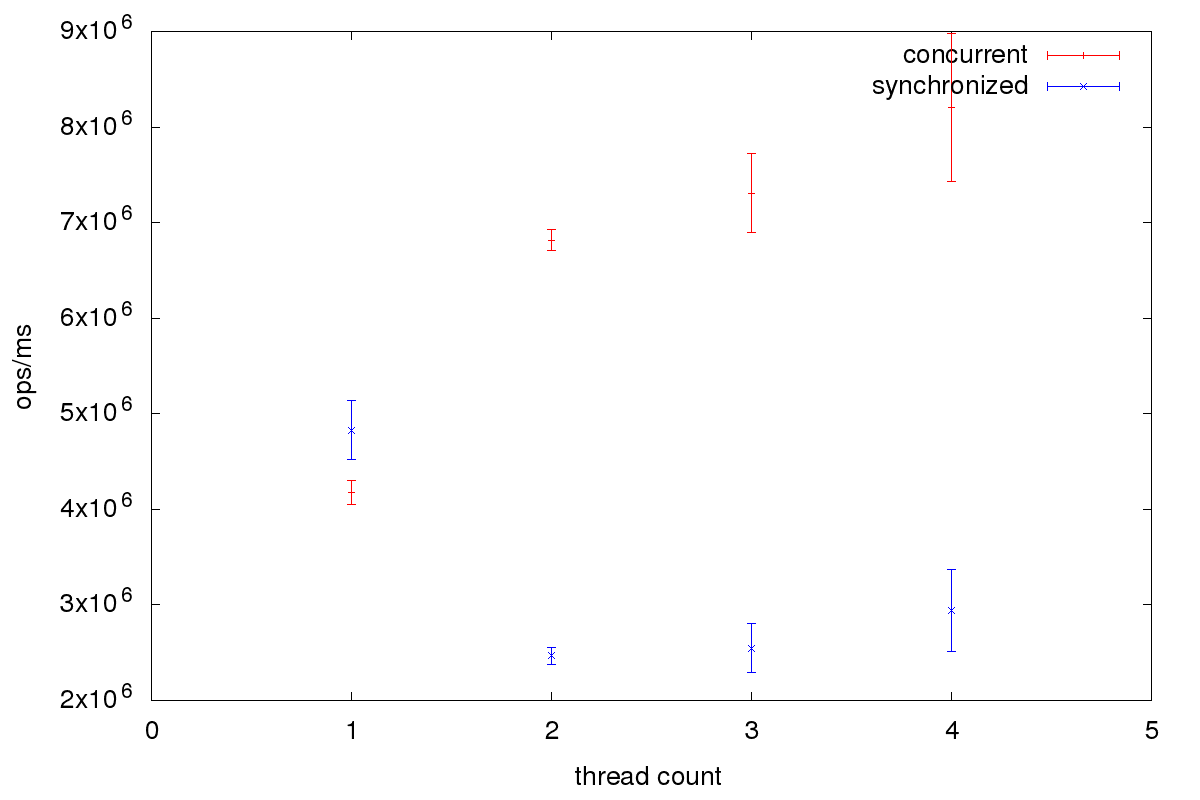
As we see the solution using ConcurrentHashMap scales better. Starting with two thread it performs better than the solution using a single lock.
Now I want an additional method to get the complete count overall cities. Here is this method for the implementation using the class ConcurrentHashMap:
public int completeCount() {
int completeCount = 0;
for (Integer value : map.values()) {
completeCount += value;
}
return completeCount;
}
To see if this solution is thread-safe I use the following test:
import com.vmlens.api.AllInterleavings;
public class TestCompleteCountConcurrentHashMap {
@Test
public void test() throws InterruptedException {
try (AllInterleavings allInterleavings =
new AllInterleavings("TestCompleteCountConcurrentHashMap");) {
while (allInterleavings.hasNext()) {
CityToCount cityToCount =
new CityToCountUsingConcurrentHashMap();
Thread first = new Thread(() -> {
cityToCount.move("Springfield", "South Park");
});
first.start();
assertEquals(2 * CityToCount.POPULATION_COUNT,
cityToCount.completeCount());
first.join();
}
}
}
}
I need two threads to test if the method completeCount is thread-safe. In one thread, I move one person from Springfield to South Park. In the other thread I get the completeCount and check if the result equals the expected result.
To test all thread interleavings we put the complete test in a while loop iterating over all thread interleavings using the class AllInterleavings from vmlens, line 7. Running the test I see the following error:
expected:<2000000> but was:<1999999>
The vmlens report shows what went wrong:
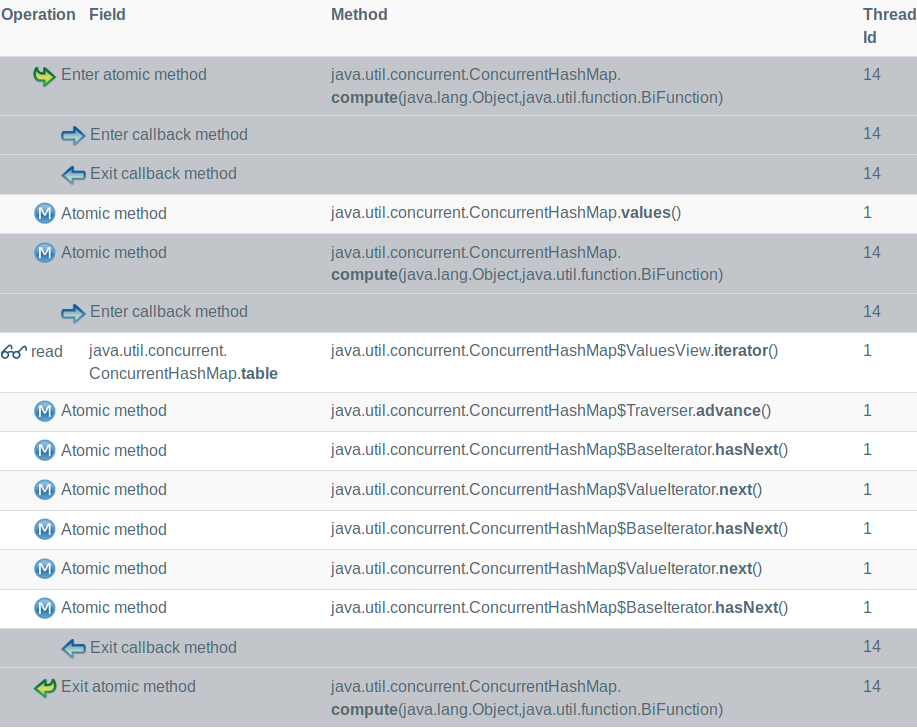
As we see the problem is that the calculation of the complete count is done while the other thread still moves a person from Springfield to South Park. The decrement for Springfield was already executed but not the increment for South Park.
By allowing the parallel update of different cities the combination between completeCount and move leads to the wrong results. If we have methods which operate over all cities we need to lock all cities during this method. So to support such a method we need to use the second solution using a single lock. For this solution we can implement a thread-safe countComplete method as shown below:
public int completeCount() {
synchronized (lock) {
int completeCount = 0;
for (Integer value : map.values()) {
completeCount += value;
}
return completeCount;
}
}
The example surely does not reflect the complexity of your data structure. But what is true in the example is also true in the real world. There is no way to update multiple dependent fields in a thread-safe way except to update them one thread after the other. So the only way to achieve scalability and thread safety is to find independent parts in your data. And then update them in parallel from multiple threads.
© 2020 vmlens Legal Notice Privacy Policy