June 16, 2020
The following shows an algorithm for a simple concurrent hash map which for writes scales better than java.. java. is fast, sophisticated, and rather complicated. And I needed a similar data structure for vmlens, a tool to test concurrent Java. I can not use java., since I also want to trace the internals of java. with this tool.
So I decided to implement only the bare minimum, the method computeIfAbsent. This led to a simple yet scalable concurrent hash map.
You can download the source code from GitHub here.
The algorithm uses open addressing with linear probing. It is based on work from Jeff Preshing, which again is based on work from Dr. Cliff Click. This GitHub repository contains the source code of the hash map from Dr. Cliff Click.
Open addressing means that the key-value pairs are stored in a single array. The index to store a key-value pair is given by the hash code modulo the array size.
Linear probing means that if this array element is already occupied, we use the next array element. And so on, until we have found an empty slot. Here is an example for an insert after two filled slots:
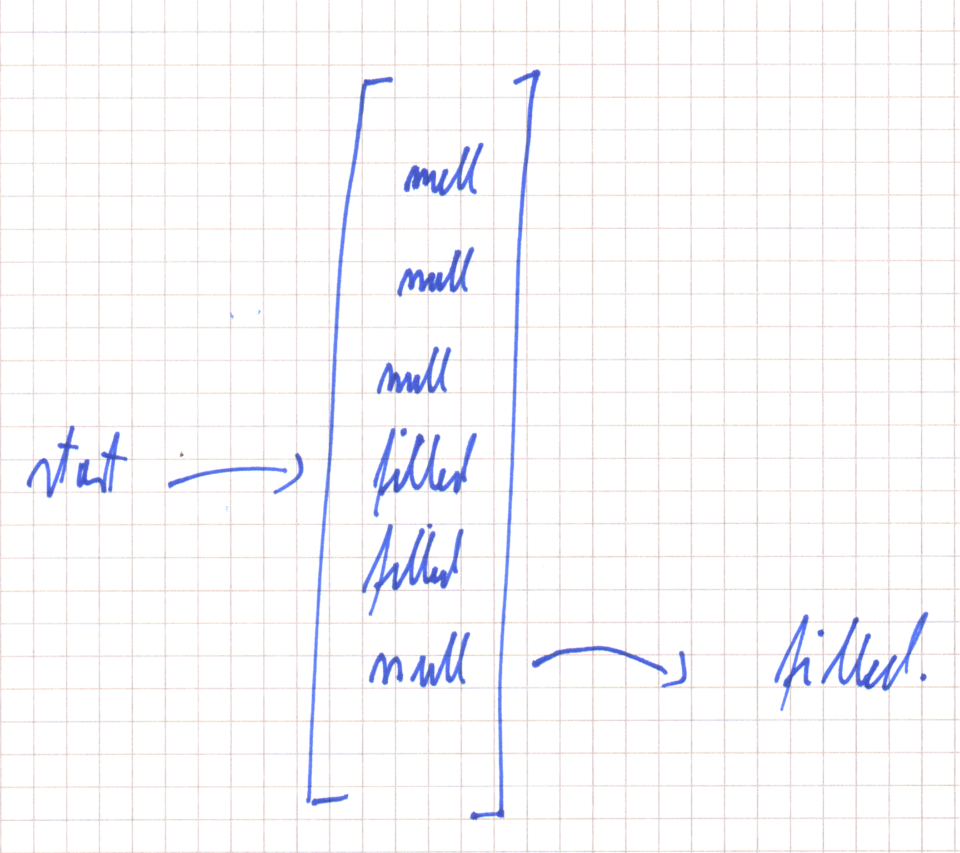
To make the algorithm concurrent, we need to fill the empty array element using compareAndSet. By using compareAndSet we make the checking for null and the setting of the new element atomic. If compareAndSet succeeds we have successfully inserted a new element. If it fails we need to check if the key inserted by the other threads equals our key. If yes we are done and can return the value of this element. If not, we need to find a new empty slot and try again.
Here is the source code for the algorithm:
private static final VarHandle ARRAY =
MethodHandles.arrayElementVarHandle(KeyValue[].class);
volatile KeyValue[] currentArray;
public V computeIfAbsent(K key, Function<? super K, ? extends V> compute) {
KeyValue[] local = currentArray;
int hashCode = hashAndEquals.hashForKey(key);
// the array position is given by hashCode modulo array size. Since
// the array size is a power of two, we can use & instead of %.
int index = (local.length - 1) & hashCode;
int iterations = 0;
KeyValue created = null;
KeyValue current = tabAt(local, index);
// fast path for reading
if (current != null) {
if (hashAndEquals.keyEquals(current.key, key)) {
return (V) current.value;
} else if (current.key == MOVED_NULL_KEY) {
return (V) insertDuringResize(key, compute);
}
}
while (true) {
if (current == null) {
if (created == null) {
created = new KeyValue(key, compute.apply(key));
}
// use compareAndSet to set the array element if it is null
if (casTabAt(local, index, created)) {
if (((iterations) << resizeAtPowerOfTwo) > local.length) {
resize(local.length, iterations);
}
// if successful we have inserted a new value
return (V) created.value;
}
// if not we need to check if the other key is the same
// as our key
current = tabAt(local, index);
if (hashAndEquals.keyEquals(current.key, key)) {
return (V) current.value;
} else if (current.key == MOVED_NULL_KEY) {
return (V) insertDuringResize(key, compute);
}
}
index++;
iterations++;
if (index == local.length) {
index = 0;
}
if ((iterations << resizeAtPowerOfTwo) > local.length) {
resize(local.length, iterations);
return computeIfAbsent(key, compute);
}
current = tabAt(local, index);
if (current != null) {
if (hashAndEquals.keyEquals(current.key, key)) {
return (V) current.value;
} else if (current.key == MOVED_NULL_KEY) {
return (V) insertDuringResize(key, compute);
}
}
}
}
private static final KeyValue tabAt(KeyValue[] tab, int i) {
return (KeyValue) ARRAY.getVolatile(tab, i);
}
private static final boolean casTabAt(KeyValue[] tab, int i,
KeyValue newValue) {
return ARRAY.compareAndSet(tab, i, null, newValue);
}
The trick is that if a thread has read a filled array element, the array element will stay filled and the key will stay the same. So the only time we need to check if another thread has modified an already read value is when we read null. We do this by using compareAndSet as outlined above.
Therefore our algorithm is possible because we do not allow to remove keys and the keys are immutable.
During resizing, we need to make sure that newly added elements do not get lost. So we need to block the current array for updates during resizing. We do this by setting each empty array element to a special value MOVED_NULL_KEY. If a thread sees such a value, it knows that a resize is running. And will wait with an insert till the resize is done.
The resize of the hash map consists of the following steps:
Here is the source code:
private static final Object MOVED_NULL_KEY = new Object();
private final Object resizeLock = new Object();
private void resize(int checkedLength, int intervall) {
synchronized (resizeLock) {
if (currentArray.length > checkedLength) {
return;
}
resizeRunning = true;
// Set all null values in the current array to the special value
for (int i = 0; i < currentArray.length; i++) {
if (tabAt(currentArray, i) == null) {
casTabAt(currentArray, i, MOVED_KEY_VALUE);
}
}
int arrayLength = Math.max(currentArray.length * 2,
tableSizeFor(intervall * newMinLength + 2));
// Create a new array
KeyValue[] newArray = new KeyValue[arrayLength];
// Copy all values from the current array to the new array
for (int i = 0; i < currentArray.length; i++) {
KeyValue current = tabAt(currentArray, i);
if (current != MOVED_KEY_VALUE) {
int hashCode = hashAndEquals.hashForKey(current.key);
int index = (newArray.length - 1) & hashCode;
while (newArray[index] != null) {
index++;
if (index == newArray.length) {
index = 0;
}
}
newArray[index] = current;
}
}
// Set the current array to the new array
currentArray = newArray;
resizeRunning = false;
resizeLock.notifyAll();
}
}
The performance of the different hash maps depends on the specific workload and the quality of the hash function. So take the following results with a grain of salt. To measure the performance I call the method computeIfAbsent with a random key using JMH. Here is the source code for the benchmark method:
public static final int MAX_KEY = 10000000;
public static final Function COMPUTE = new Function() {
public Object apply(Object t) {
return new Object();
}
};
@Benchmark
public Object computeIfAbsentHashMap() {
int key = ThreadLocalRandom.current().nextInt(MAX_KEY);
return computeIfAbsentHashMap.computeIfAbsent(key, COMPUTE);
}
You can download the source for the benchmark code from GitHub here. Here are the results for Intel Xeon Platinum 8124M CPU @ 3.00GHz with two sockets with eighteen cores per socket each and two hardware threads per core. I used Amazon Corretto 11 as JVM.
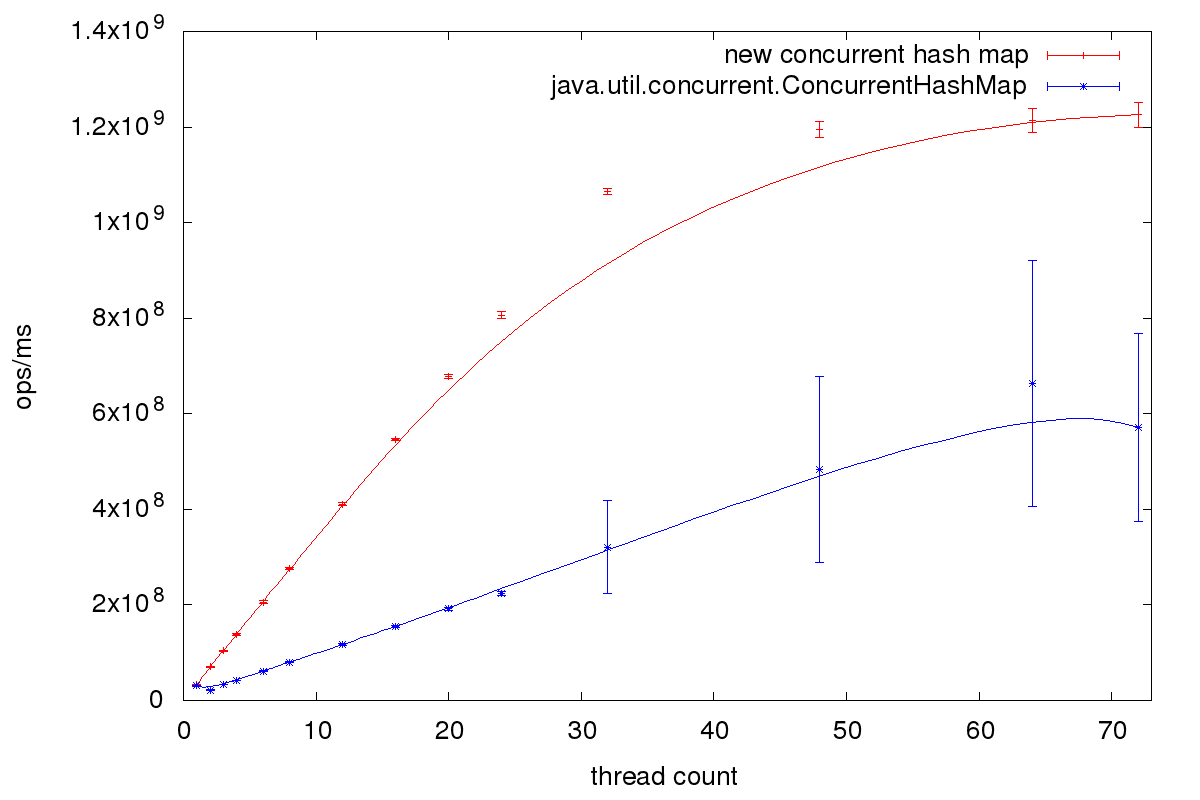
The size of the map is similar to the size of ConcurrentHashMap. For five million random keys java. needs 285 megabytes and the new map 253 megabytes.
The new map retries to insert an element if another thread has updated an empty slot. java. uses the array bins as monitors for a synchronized block. So only one thread at a time can modify the content of those bins.
This leads to the following difference in behavior: The new map might call the callback method compute multiple times. Every failed update leads to a method call. java. on the other side only calls compute at maximum once.
By implementing only the computeIfAbsent method, we can write a concurrent hash map which for writes scales better than java.. The algorithm is so easy because we avoided the deletion and the change of keys. I use this map to store classes together with related metadata.
© 2020 vmlens Legal Notice Privacy Policy